1.3 Ways to reproduce articles in terms of release date and magazine
Authors: Mikołaj Malec, Maciej Paczóski, Bartosz Rożek
1.3.1 Abstract
Reproducibility is a topic that is quite diminished in today’s science world. Scientific articles should be current as long as possible. Their results should be achievable by readers and be the same. Thanks to that science and business world can take advantage of them. The more article is difficult to reproduce, the chance of using knowledge coming from it is smaller. Many researchers tried to define or give principles for reproducibility. There is an article published in 2016: “What does research reproducibility mean?” (Goodman, Fanelli, and Ioannidis 2016b) which tried to warn about reproducibility crisis. Article in 2017: “Computational reproducibility in archaeological research: basic principles and a case study of their implementation” (Marwick 2016), compared computational reproducibility to archaeological research and give guidelines for researches to use reproducibility in computing research. But these are just two of many articles about reproducibility. Some articles are about tools and techniques for computational reproducibility (Piccolo and Frampton 2016). They encourage researchers to compute data using environments like Jupiter (Thomas et al. 2016) or R markdown (Marwick, Boettiger, and Mullen 2017). Thanks to that readers can reproduce finding on their own. What’s new about our approach to the subject of reproducibility is focusing on how can release date and magazine affect the amount of work needed to fully reproduce code or is it even possible. A comprehensive comparison of scientific magazines in terms of reproducibility is yet to be created and this article is our best effort to make it happen.
1.3.2 Methodology
Our work was focused on analyzing journals as a whole, therefore we decided to choose three well-known magazines: R Journal, JMLR Machine Learning Open Source Software, and Journal of Statistical Software. Our aim was to define features that incense the reproducibility of a journal’s article as well as the ones that impede it. We would like to create a list of rules that improve and enable reproducibility.
We divided the magazines, every one of us gets one to look up. Every one of us gets the different approaches to their magazine. Mostly it considered getting familiar with the magazine, like their style or rules for applying the article, but most importantly we looked at random articles to get a fill how one could replicate the results and would it worked.
Because reproducibility can be achieved in many ways, we didn’t make specific rules when an article can be replicated. An article is more likely to be able to be reproducible if it has such features. We weren’t keen on replicating whole articles. We were more interested in looking for features, which would help in the reproducibility of an article.
Features mostly took into consideration:
Source code included in an article or added as a file ready to download
Accessibility of data used in an article
Availability of packages presented and used in an article
Information about device and environment
We used many methods to extract the quantity and quality of these features from magazines. In some cases, information was easy to get manually, so no more code was written.
In another case, a scraper written in Python helped us collect the required information. Scraper for R and if the is on Cran respiratory. If not it checks when the package was (for how long was this article was reproducible).
In the case of JMLR information about the link to author respiratory was by copying text on and counting words ‘abs’ and ‘code’. All articles have ‘[abs]’ and some have ‘[code]’ if they have a link to the author’s respiratory.
We compare them by pointing their strengths and weakness, which we discovered. It will be automatically a set of guidelines for magazine publishers and researches which features should be included so their future articles would be reproducible easily.
1.3.3 Results
R Journal
‘The R Journal is the open access, refereed journal of the R project for statistical computing. It features short to medium length articles covering topics that should be of interest to users or developers of R. The R Journal intends to reach a wide audience and have a thorough review process. Papers are expected to be reasonably short, clearly written, not too technical, and of course, focused on R’ ~ R Journal.
It is a well-known magazine, which has a clear page and it is easy to find every article in the archive which contains all previous releases. Every article has its page with features such as short description, necessary CRAN packages, and supplementary materials. A list of packages contains links to CRAN. Here the first problem is spotted - not every package has the current version on CRAN or the page has error 404 - “Object not found”. When the package is not easy to download, install, and use, the reproducibility is significantly harder and when it is unobtainable reproducibility is simply impossible. The part of packages available on CRAN is shown in Figure ###. As it is said on the main page of R Journal - ‘Authors of refereed articles should take care to (…) provide code examples that are reproducible’, in 2016 ‘supplementary materials’ were introduced. It contains a link to download additional files such as R scripts, that allow the reader to reproduce things contained in the article e.g. plots and calculations. The link is located in every article’s page and part of articles having it is higher every consecutive year (shown in Figure 2).
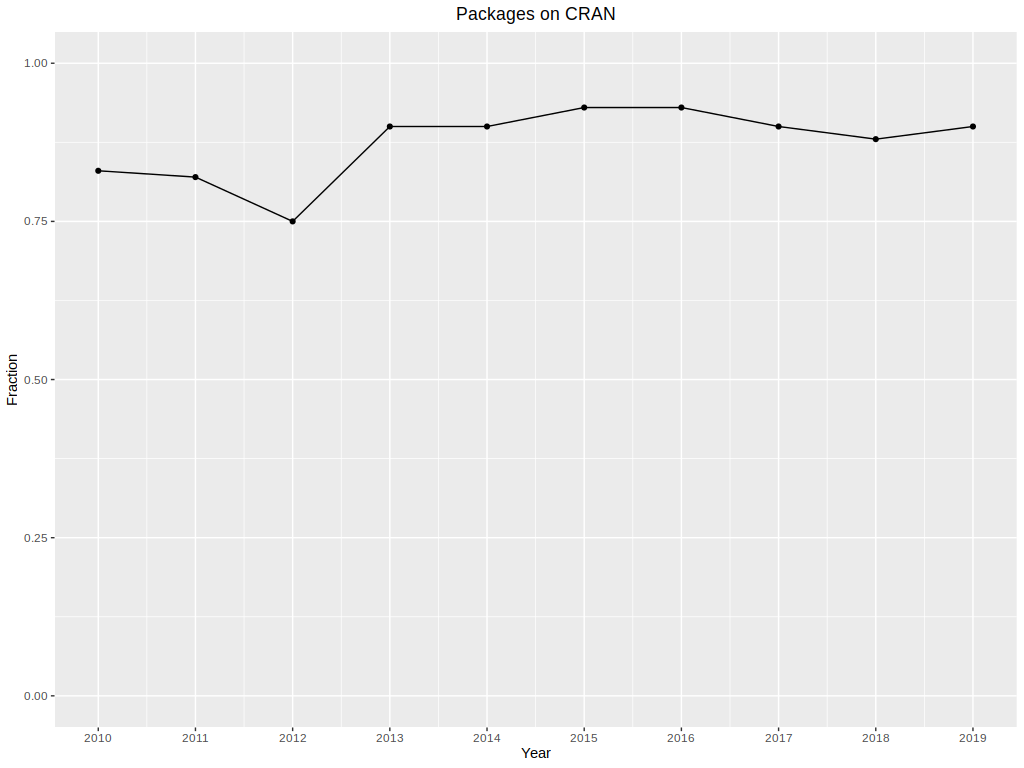
Figure 1
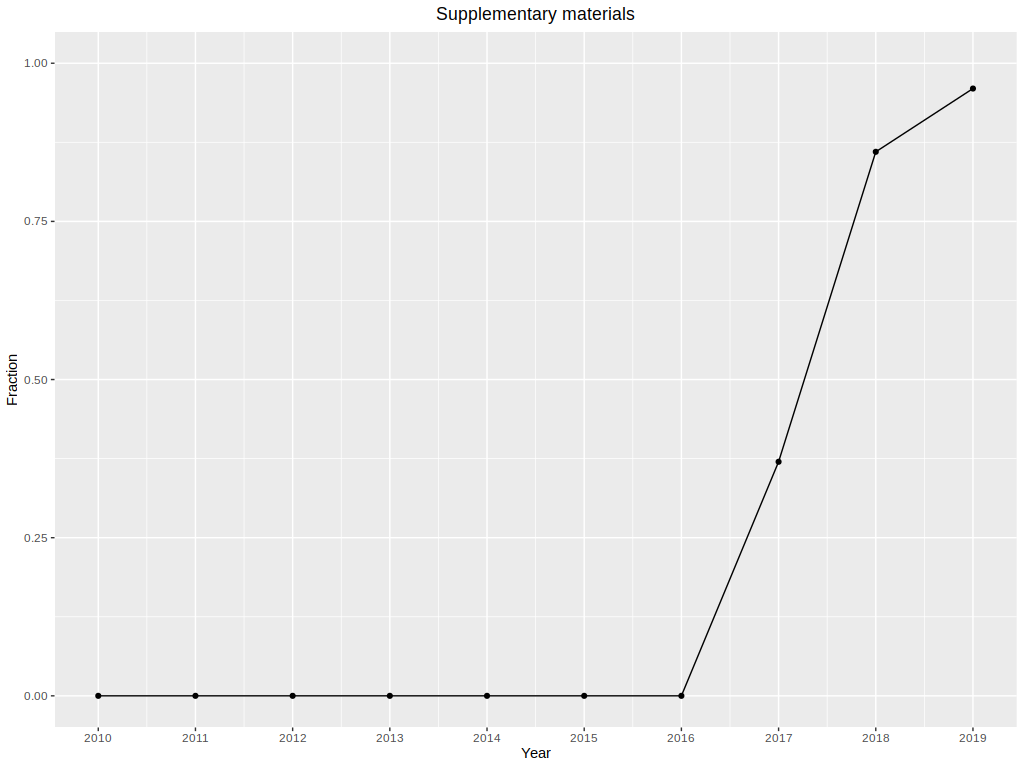
Figure 2
Journal of Statistical Software As stated on the journal website “The Journal of Statistical Software (JSS) publishes open-source software and corresponding reproducible articles…” articles published by JSS should be easy to reproduce. By going through all available articles we want to examine how much effort is put into keeping JSS articles reproducible. Journal of Statistical Software first started publishing in 1997 and gradually increased both number of articles per year and the percentage of articles discussing R. Starting from 13 articles per year they peaked in 2011 almost crossing the barrier of 100 articles published that year (Figure 3).
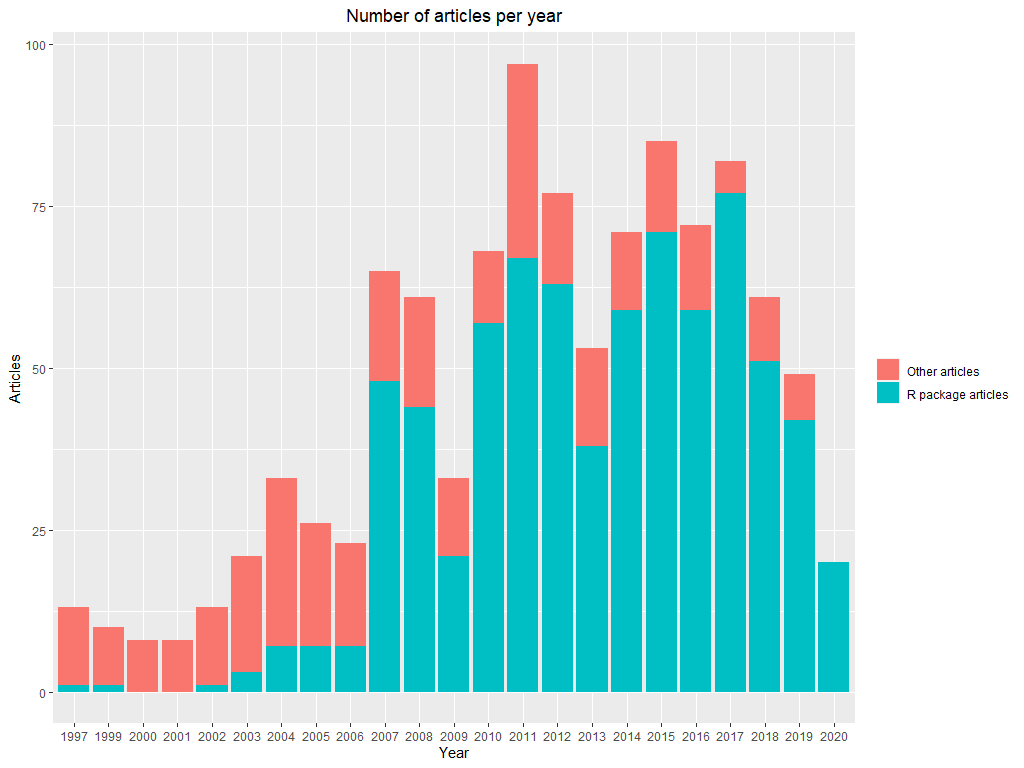
Figure 3
The thankfully growing scale of the journal did not lead to less attention given to the topic of reproducibility. Each of 744 articles discussing R packages is published alongside with R file containing example code and described version of R package. However as stated at the JSS website, the journal does not serve as a software repository for software distribution, so it is not possible to update code or articles once they were published. That is why JSS suggests that software should also be available in the standard open-source repository. While trying to reproduce the article, it is discouraging to discover that the described package is no longer available on CRAN. Nevertheless, packages appearing in JSS articles are mostly available to download from CRAN (Figure 4).
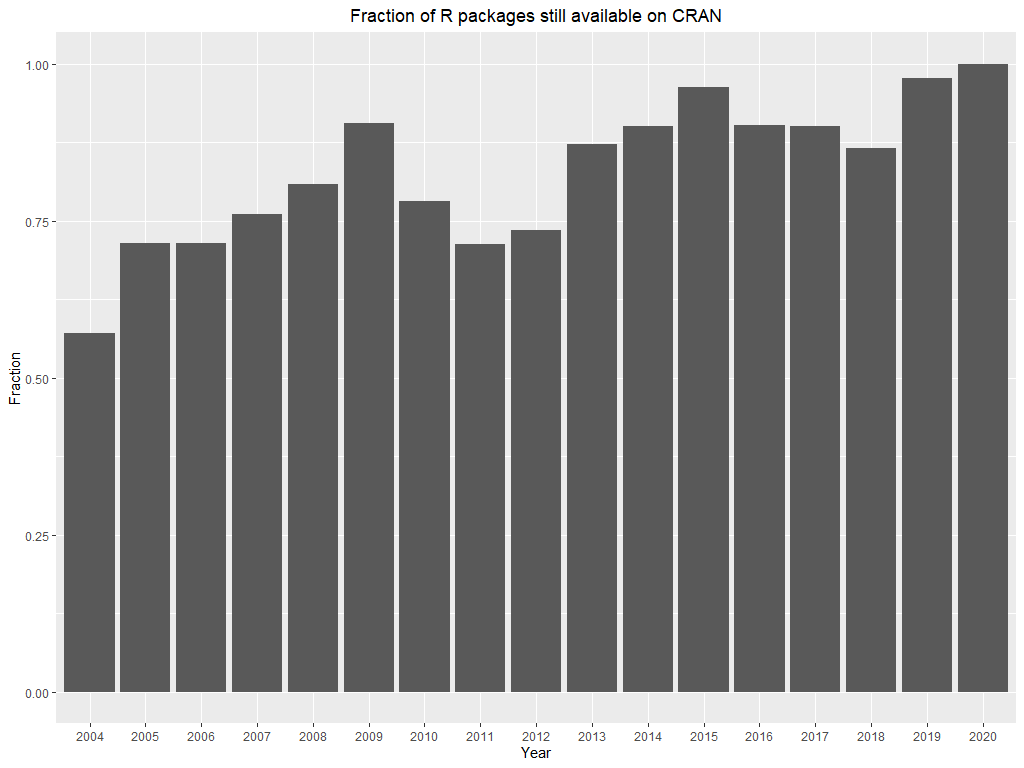
Figure 4
Another interesting aspect of the reproducibility of R related articles is the difference between the date of submission and publication. In other words how outdated was article when it appeared on JSS and if it is more difficult to reproduce such articles. Articles published and 2020 were on average submitted almost 3 years ago, which may result in some issues while trying to reproduce given code (Figure 5).
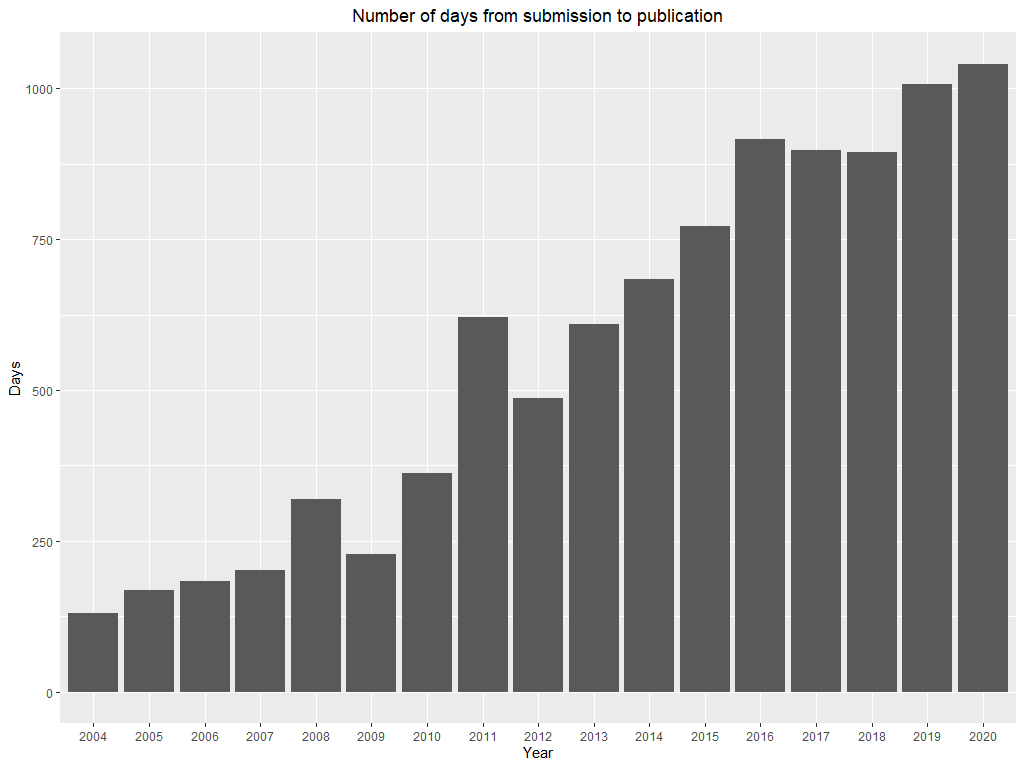
Figure 5
In a perfect scenario, the version of the package on which the article is based should always work with example code, therefore any updates on CRAN would lower the reproducibility. However in reality many things can change - dependencies can get updated or the current R version may change. Based on that we will look at package updates like the ability to adapt and keep software compatible with past code and treat them as feature increasing reproducibility. As presented on figure average time since the last update of the package described in the JSS article is not unreasonable and should not pose a threat to reproducibility (Figure 6).
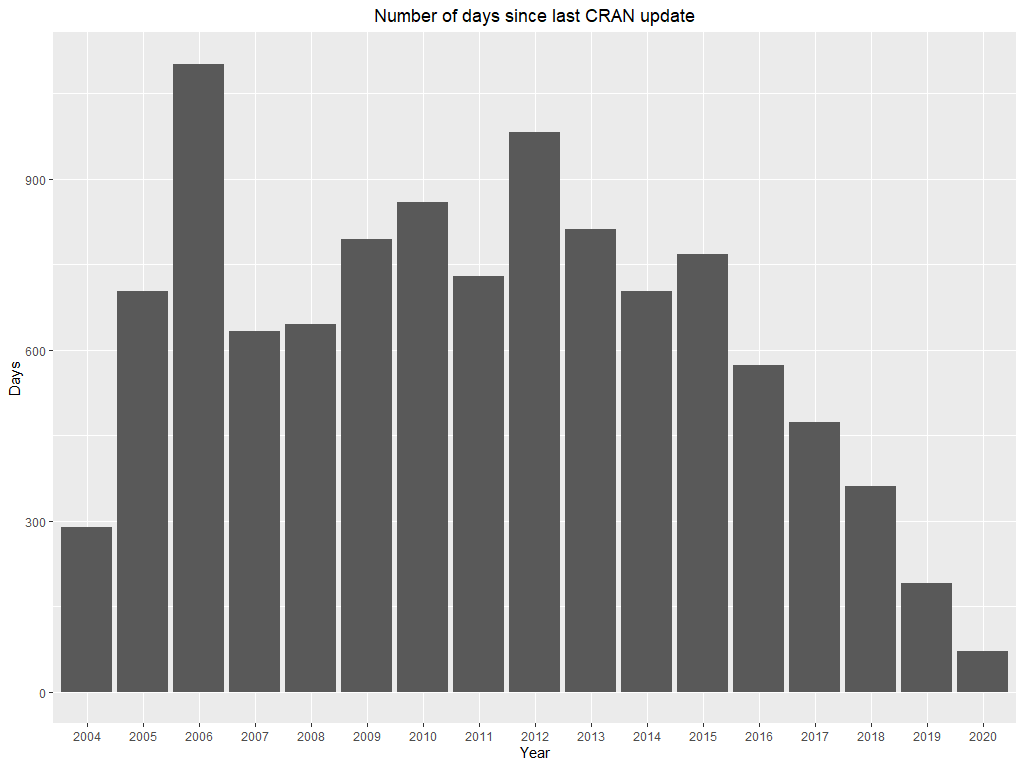
Figure 6
JMLR
The Journal of Machine Learning Research (JMLR) is an international forum for the electronic and paper publication of high-quality scientific articles in all areas of machine learning. All published works are available free of charge on the Internet.
For the most part, the authors do not include code or references to their sites. Magazine administrators encourage you to post your code.
Unfortunately, few authors apply to it. This does not mean that content of the articles is unreliable, but it makes articles unreproducible. The items included in the articles that should be reproduced are experiments on data sets and the code that was used to create the final tables/charts.
However, some articles have a reference [code]. Most often it refers to the author’s repository (e.g. GitHub). The reproduction of such an article then depends on the author and how he created his code. Links began to appear from 2011 (the first article was in 2001). Over the years, there are more and more articles with links with code, but these are still a minority. Administrators have created a special tab with articles that have a link with a code, probably to popularise such links.
Fortunately in the newest article (still in production) has record links with code. More than 20 and near half of the posted articles have this link. There could be a drastic change for this magazine.
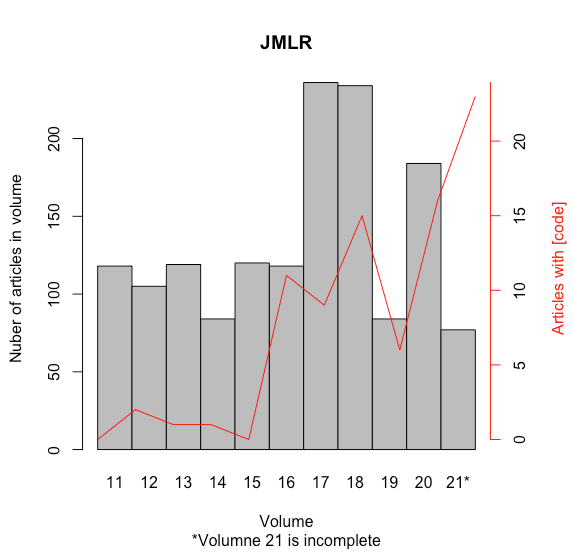
Figure 7
Summary and conclusions
Careful analysis of mentioned journals revealed which features while writing and publishing article lead to boost to reproducibility and which make the task of code reproducing more difficult. Good practices such as publishing articles alongside R file containing example code and supplementary data. The unified way of naming and hosting those files is also welcomed. Solutions like distributing articles including links to authors Github profile or described package CRAN website are increasing journal reproducibility. The Journal board may also take actions like encouraging authors to ensure if the package is compatible with published code or simply supplying readers with easily accessible contact with the writer. One thing that journals lack is a clear way of informing readers whether the article is ready to be reproduced, for example, if all required files and data are available for download. Below is our vision of accomplishing that (Figure 8).

Figure 8
References
Goodman, Steven N., Daniele Fanelli, and John P. A. Ioannidis. 2016a. “What Does Research Reproducibility Mean?” Science Translational Medicine 8 (341). https://doi.org/10.1126/scitranslmed.aaf5027.
2016b. “What Does Research Reproducibility Mean?” Science Translational Medicine 8 (341): 341ps12–341ps12. https://doi.org/10.1126/scitranslmed.aaf5027.Marwick, Ben. 2016. “Computational Reproducibility in Archaeological Research: Basic Principles and a Case Study of Their Implementation.” Journal of Archaeological Method and Theory 24 (2): 424–50. https://doi.org/10.1007/s10816-015-9272-9.
Marwick, Ben, Carl Boettiger, and Lincoln Mullen. 2017. “Packaging Data Analytical Work Reproducibly Using R (and Friends).” The American Statistician 72 (1): 80–88. https://doi.org/10.1080/00031305.2017.1375986.
Piccolo, Stephen R., and Michael B. Frampton. 2016. “Tools and Techniques for Computational Reproducibility.” GigaScience 5 (1). https://doi.org/10.1186/s13742-016-0135-4.
Thomas, Kluyver, Ragan-Kelley Benjamin, Pérez Fernando, Granger Brian, Bussonnier Matthias, Frederic Jonathan, Kelley Kyle, et al. 2016. “Jupyter Notebooks &Ndash; a Publishing Format for Reproducible Computational Workflows.” Stand Alone 0 (Positioning and Power in Academic Publishing: Players, Agents and Agendas): 87–90. https://doi.org/10.3233/978-1-61499-649-1-87.