Don’t delete your missing data - learn how to deal with it.
All the data we have
We learn on clean fabricated datasets but when it comes to real life problems machine learning becomes something completely different. Very often we must deal with missing values. A common approach is to simply delete observations that have them but by doing so we can lose a lot of important information. That is the main reason why we should be “data imputation ninjas” as it can save us a lot of time when trying to find a model fitting our data well.
Many cases - many solutions
Missing values can be very different for each dataset. They might be completely random, follow some pattern or simpy be a part of data model. That’s why there is no approach that always performs best. To dive deeper into the topic Jan Borowski, Filip Chrzuszcz and Piotr Fic from Warsaw University of Technology wrote an article about various data imputation techniques in r
Diving deeper
The article mentioned above explains in a complex way what are the algorithms for data imputation available in R and how they perform on various datasets. There were 14 datasets with percentage of missing values varying from 0.7% to 35.8%. After preparing the datasets several imputation methods were tested and feeded into 4 different machine learning algorithms. Tested imputation methods were:
- mean/mode imputation - replacing missing continous values with mean and replacing missing discrete values with mode of remaining ones,
- mice (predictive mean matching) - multivariate imputation by chained equations,
- missMDA - imputation with the principal component method,
- missFOREST - imputation with predictions of the random forest model,
- softImpute - solving an optimization problem using a soft-thresholded SVD algorithm for continous variables
- VIM - iterative robust model-based imputation
All of the tasks were classification and the algorithms used for testing were:
- Extreme Gradient Boosting,
- Random Forest,
- Support Vector Machines,
- Linear Regression
What works better?
The two measures used for evaluating models were F1-score and accuracy. All the models were done the same way with only imputation methods differing between them. Eventually for each of the 14 datasets the average score was taken and that’s how they realized that there isn’t one imputation method that works the best.
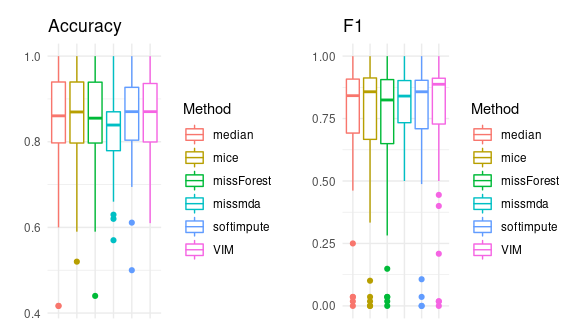
Plot shows average scores across all datasets for different imputation methods
We can see that there is no obvious leader. That’s why ranking system was introduced giving bigger scores for worse predictions. The apporach with least points should turn out to be least case specific and generally the best.
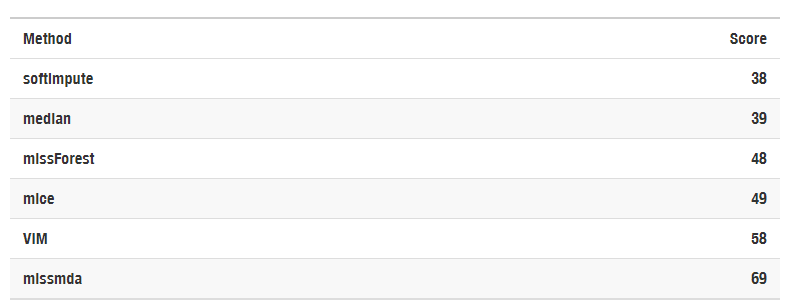
Table with imputation methods ranking
Another thing that has to be taken into consideration is time of imputation.
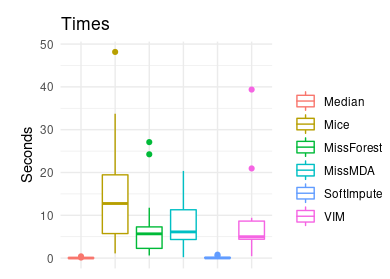
Average time of imputation for different methods
What should I use for my data?
Based on the article the best imputation method depends on the problem but it is always worth to begin with median/mode imputation as it is very little time consuming and can significantly improve your model. Only if the results are not satisfying we should then try other ones. For more refer to the article.