What __ a data imputation?
Far far away, beyond the seven hills, there are data scientists, data analysts, consultants who don’t have a single thought whether the data they deal with contains any missing values. Unfortunately, we do have to think about it. A lot… The question everybody strives to answer is how to do it properly, efficiently, and effectively at the same time.
Fortunately, the group consisting of Paulina Przybyłek, Renata Rólkiewicz, Jakub Wiśniewski, and Jakub Pingielski (henceforth Authors) has recently faced the challenge of finding the best imputation methods to solve our problems once for all. Their research was comprehensive, like the results.
Full paper and robust description can be found at Default imputation efficiency comparison
___ methodology
Authors came up with an idea of creating a versatile pipeline to test as many imputation method - classifier - dataset threes as they could. They ended up with almost 500, which is impressive.
What is worth additional noticing is that they didn’t stop at the median / mean kind of imputation methods but also tried more sophisticated ones like missForest or mice. What’s more - Authors didn’t base on one metric and used 4: ROC AUC, Balanced Accuracy, Geometric Mean and Weighted TPR-TNR (sidenote: those metrics are used for slightly different kinds of problems, so their results are going to give a broader image of imputation methods performance).
Although Authors tested only small and medium-size datasets (5K observations isn’t that big) obtained results can be at ease applied broadly.
What ___ the results?
Many conclusions can be driven out of the mentioned research but one takes the first place. What turned out is that simple, basic imputation methods (except harsh column removing) perform the best across datasets and models (even random fill!). Furthermore, the Authors created another contest metric - the time of calculations, which is fair, because imputations taking several hours or days to finish are relatively not usable at all.
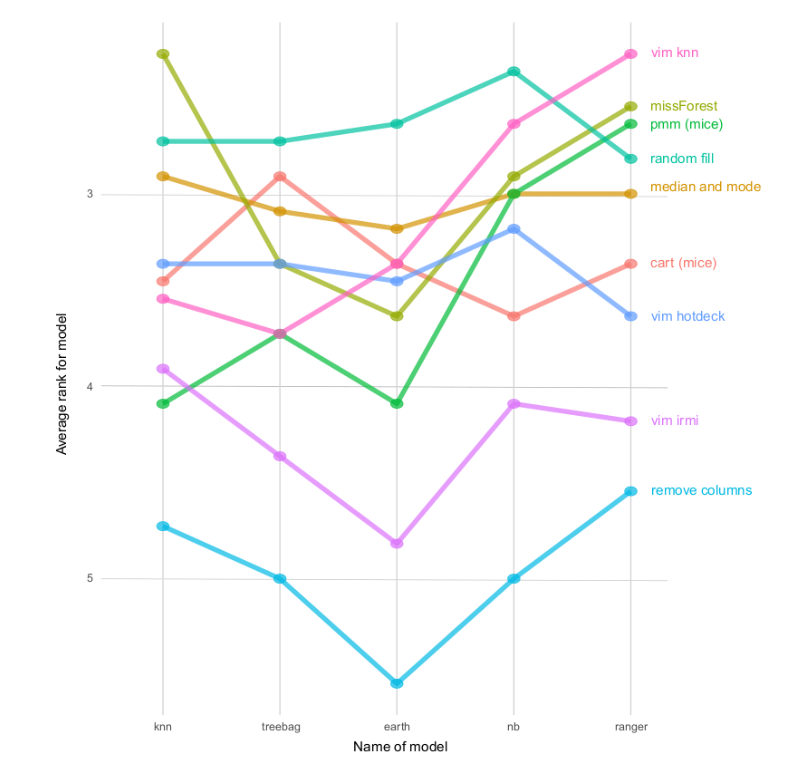
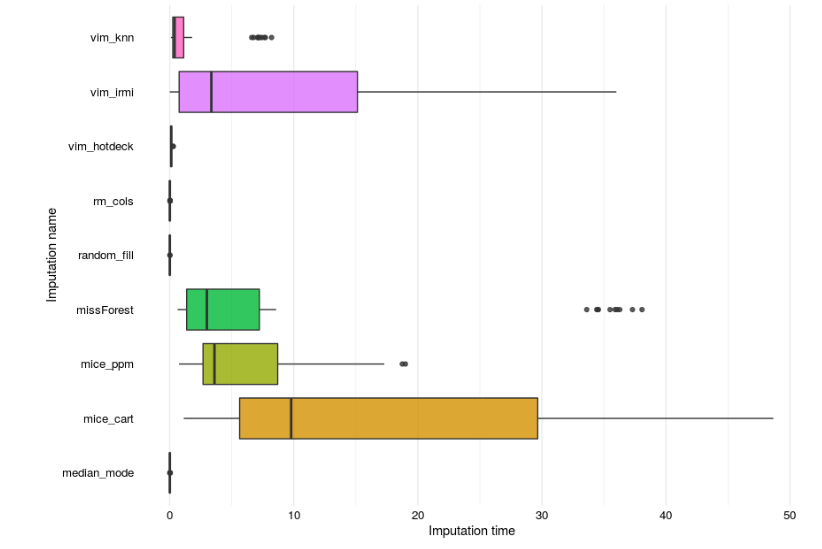
No hardcore data scientist is necessary to interpret the above graphics properly. As mentioned, basic imputation methods create presumably the biggest gains compared to final classifiers’ performance.
What was lacking is the business and real-life interpretations of those best methods. It is totally fine to get a median in the Iris dataset sepal length feature but shouldn’t be freely considered in more sophisticated data e.g. medicine, or sensitive business processes. Anyway, that niche can be filled with more complicated methods like mice or missForest, which create bigger variance and more thoughtful values to impute with.
Summing __
Authors came through creating a reliable pipeline to test the performance of many imputation methods and they did it very conscientiously. The range of chosen methods, datasets, and even classifiers is striking. Although there are some inconveniences no one should dare say that the Authors didn’t consider any aspect of the problem.
The research was carried out scrupulously, so even though imputation brings always some imperfections to the data, they managed to diminish them almost utterly.