Our story begins
The story of Hajada is perhaps not an Arabian epic, but still, but just like one of Shecherezade’s stories, it’ll keep you, dear Reader, on your toes. Sometimes, the data is incomplete and we need to cope with that. There are many methods of so-called “imputation’’, i.e. filling gaps in the data. Hanna Zdulska, Jakub Kosterna, Dawid Przybyliński took an effort to compare those methods. Here’s what they found out.
Challengers approach
What kinds of imputation did they compare? The popular ones, you may know them or not, namely: “Bogo replace”, replacing with mode or median, “MICE” imputation method, “missForest” imputation and “VIM’s k-NN”. “Bogo replace” is a simple method of replacing missing values with random values from the same column and different observations. Replacing missing values with mode or median of a column is self-explanatory. In “MICE” we create multiple imputations for multivariate missing data, based on so-called “Fully Conditional Specification”, where each incomplete variable is replaced by a separate model. “missForest” is an imputation method based on fandom forest and “VIM’s k-NN” - an imputation method based on the k-NN classifier. All of those methods have been compared with rows removal, i.e. removing rows with missing values.
Battlefields full of gaps
What datasets did they use to test those methods? Unfortunately, the variety of problems in statistical modelling is large and therefore, it’s difficult to choose a representative set of classification tasks. The fellowship chose 6, as they say, “awesome” datasets from the “openml” website. These datasets used to test imputation methods concern only binary classification problems.
The Judges will be…
How to measure imputation correctness? It’s not a trivial question, but the team has found a brilliant solution. The idea is simple. Imputation methods are compared based on the post-imputation performance of several classification algorithms. If an imputation method produced greater performance gain than another, it’s considered the better one.
The classification tree is a machine learning classifier that learns a tree of binary decisions. The implementation they used comes from the “rpart” package. k-Nearest Neighbours (k-NN) is a simple classification algorithm that compares a new observation with observations in a training dataset, finds the most similar and makes a prediction based on their labels. Naive Bayes, as they say: “naive, but not stupid”, is another well-known classifier. Its naiveness comes from the assumption of independence of predictors. Ranger is an implementation of the random forest classifier. Its core idea is to create a set of classification trees and let them vote. Last, but not least, we have support vector machine classifier (SVM). Based on logistic regression, it’s anything but linear. In the beginning, it smartly transforms data, which people call “the kernel trick”.
The performance of the models has been measured in MCC and F1 score. The team also compared the times required to impute data.
The True King
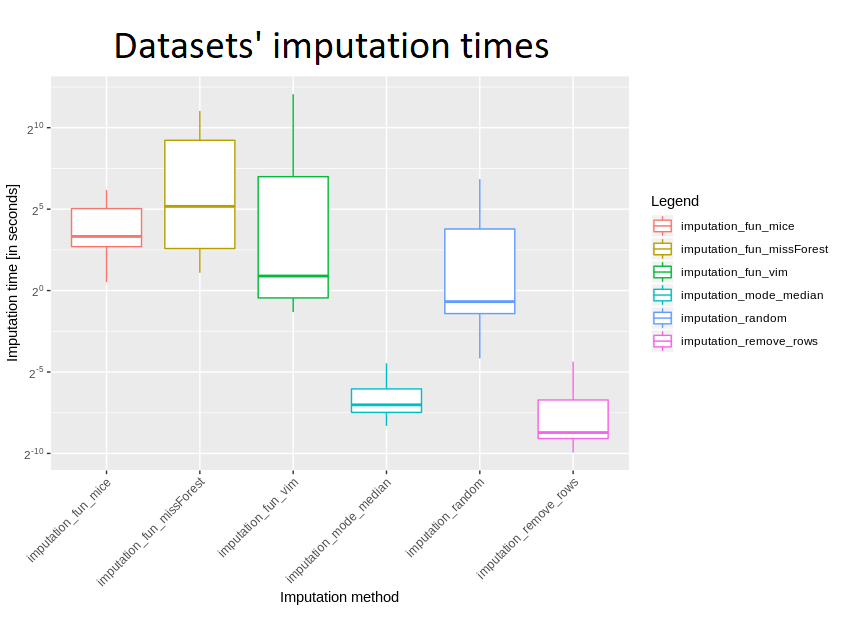
It turned out that imputation with mode or median and rows removal are the fastest methods (no surprise). Most importantly, VIM having very low median time has also the biggest variance of all.
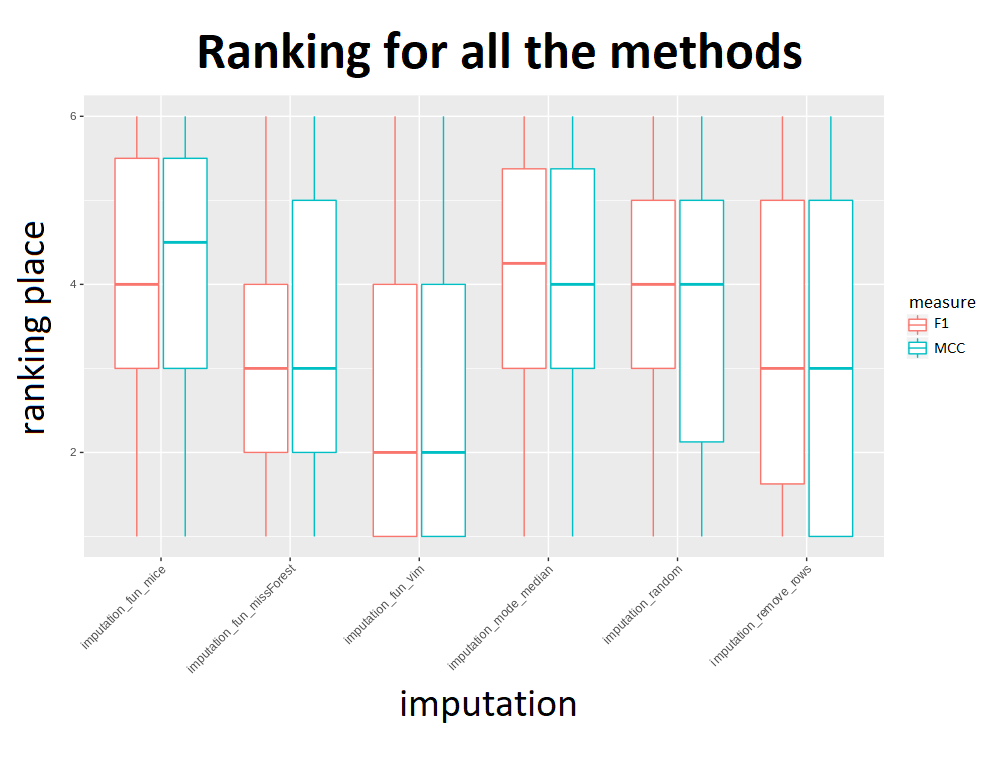
What about performance gain? Well, the best is for sure VIM, achieving the best median rank overall, and missForest the second after it. The worst methods turned out to be MICE, imputing with random values and imputing with mode/mean, achieving worst scores in F1 and MCC. The results of other methods differ if we choose to include failed imputations in our benchmark. With failed imputations, median scores of all methods are very similar.
Epilogue
At last, the best imputation method overall turned out to be VIM, among the fastest - replacing with the mode or the median and among the slowest - missForest. The mission of finding the best method of imputation has been accomplished and the fellowship of Hajada returned home, awaiting new exciting adventures in statistics.
The end.