What is this blog entry about?
Black-boxes are commonly used in computer vision. But do we have to use it? This article looks at this issue and we try to understand it with our small (but developed after one semester of machine learning experience) brains and summarize it here.
What is this article about?
Computer vision is cool. But it would be just as cool to understand how it works, and it’s not so obvious. Explainable methods of image recognition - which is de facto classification - cannot use logistic regression and decision trees, because every model loses transparency as its performance increases - not to mention understanding neural networks. That’s why the authors stated that the best for research will be good ol’ k-NN, which uses grouping of the most similar results. However, there is a problem with how to measure this similarity of images.
B-but how?
The solution to the aforementioned problem applied by the authors is embedding. But what does that even mean? The simplest way to explain it is to reduce the dimensions of images and present their content in a way that is understandable to the computer.
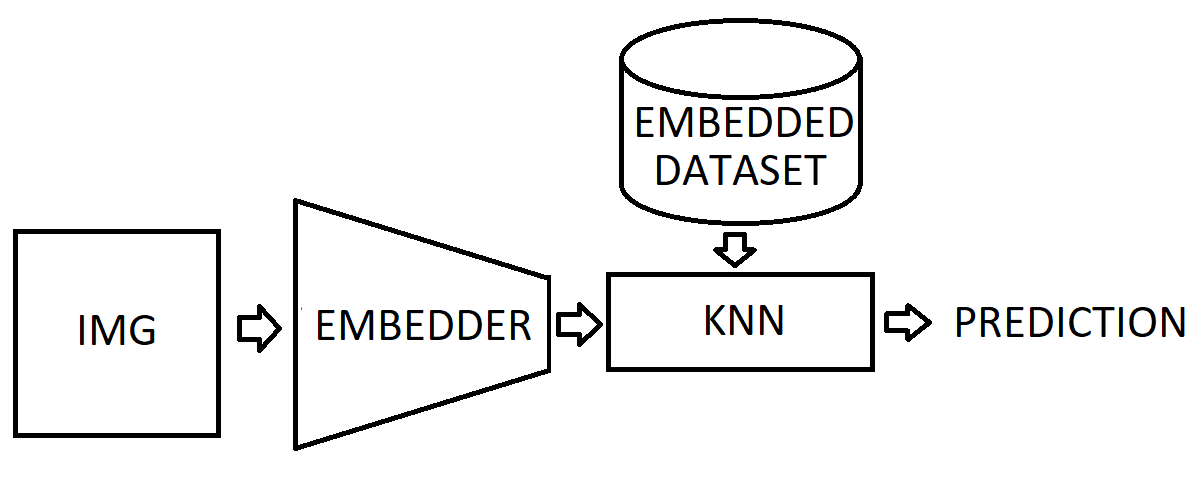
In the article, the authors present several different methods by which you can approach the problem of teaching models to recognize images. The aim here was to compare their chosen model with a more advanced and thus less interpretable model. Embedders were used for the selected k-NN:
- convolutional - actually it’s another black-box, so it’s no use writing about it
- SVD - it is some kind of linear transformation by an array of the largest eigenvectors
- K-means - the algorithm is executed, and then the centroids chosen by it are used
The output model used as a basis for comparing the results is the Convolutional Neural Network (another black box). To compare the results, the authors used the ACC (accuracy) measure, which is the ratio of correctly matched images to all of them. There is no need to use more complicated metrics, because the data set has been prepared in such a way that separate classes are equal, providing the possibility of simple measurement of model performance.
Yes, and?
| Model | ACC |
|---|---|
| Black-Box Convolutional | 0.941 |
| k-NN Convolutional | 0.923 |
| k-NN base | 0.8606 |
| k-NN K-means | 0.8512 |
| Logistic regression | 0.847 |
| k-NN SVD | 0.8001 |
Black-box was the best, but you have to reckon with that, because sometimes you can’t do something as good as the uninterpretable model. The best interpretable model was k-NN with the convolutional embedder, but unfortunately it is also only semi-interpretable. k-NN and k-NN with k-means itself did relatively well, but it turned out that k-NN with SVD conversion had lower results than the base k-NN. This transformation didn’t help at all, but even hurt. It should also be noted that in case of using K-means the process was much faster than with the base k-NN. To sum it up: using Convolutional embedder got us second-best results and while it is semi interpretable it is still better than base k-NN and logistic regression which turned out to be not interpretable.