Black vs white
Machine learning seems to be all about creating a model with best performance - balancing well its variance and accuracy. Unfortunately, the pursuit of that balance makes us forget about the the fact, that - in the end - model will serve human beings. If that’s the case, a third factor should be considered - interpretability. When a model is unexplainable (AKA black-box model), it may be treated as untrustworthy and become useless. It is a problem, since many models known for its high performance (like XGBoost) happen to be parts of the black-box team.
A false(?) trade-off
So it would seem, that explainability is, and has to be, sacrificed for better performance of the model. Brave students of Warsaw University of Technology challenged that claim and attempted to create a fully explainable model with black-box accuracy. In this article their methods and outcomes are described.
There is a way
The brave students knew, that the task was difficult, so they did their homework and prepared accordingly. They bet on extensive feature engineering - imputation, getting rid of skewness and curbing the outliers. The game-changer however was the SAFE (Surrogate Assisted Feature Extraction) algoritm. Essentialy, it silently uses a black-box model to choose important features; to separate the wheat from the chaff, so to speak. The attempt proved to be a success - on the data chosen for the work, they managed to train a decision tree, which was more accurate than standard black-box models (random forest, ADAboost, XGboost). The final results - including influence of preprocessing and feature engineering - can be admired on the plot below:
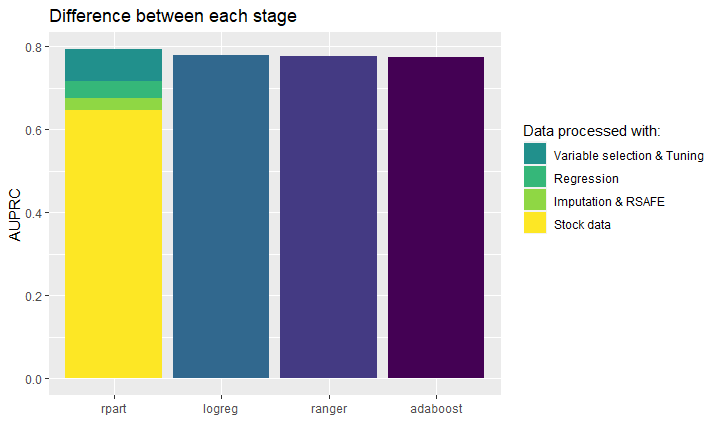
Inevitable?
Although it would seem, that the black-box models are superior, this paper proves otherwise. It reminds us of utility lying in the good, old, simple methods and challenges the supremacy of the unexplainable ones. In the end, the lesson is almost poetic - with enough work, you can train a model as accurate as XGBoost and as transparent as a decision tree.